<IT情報・コンピュータ基礎編> IT情報TOPヘ
文字コード入門
(2006年04月25日)![]()
コンピュータは基本的に「0と1」の2種類の数値を使って、数値を計算をする機械として発明されました。ところが、現在のパソコンは数値計算は勿論ですが、主として文字や画像を扱うことが多くなりました。
今回はコンピュータ上で、文字をどのように扱っているか、その基本をみていくことにします。図表は主として「日本語と文字コード」を参照させてもらいました。
<コンピュータ上で扱われる数値と表記法>
「0と1」の2種類で表す数値は、2進数(binary
number)と呼び、2進数1桁を1bit (ビット,小文字bで表示)といいます。さらに、8bit をまとめて1Byte
(バイト,大文字Bで表示)といいます。
また、2進数は桁数が多くなり人間にとって扱いにくいので、2進数を4bit
ごとに区切って16進数として表記することもあります。この場合、下記のように2進数の「0000」~「1001」は、10進数の「0」~「9」に対応させますが、「1010」~「1111」は、アルファベットの「A」~「F」の6つに対応させます。16進数2桁で1バイトになります。
この「A」~「F」
は数値で、文字ではありません。ある数値が16進数であることを明示するために、数値の頭に「0x」をつけて区別したりします。

<文字コード>
コンピュータは「0と1」の組み合わせで全ての情報を処理しますが、文字のような多くの種類がある情報は、特定の文字ごとに2進数を対応させて扱います。 コンピュータ上で文字を2進数に対応させたものが「文字コード」です。そして文字を2進数に対応させることを、「コード化」(エンコードまたは符号化ともいう)するといい、コード化された文字を「テキスト」といいます。
欧米などで使われる英数字の文字コードは、ASCII (American Standard Code for Information Interchange)が世界標準となっています。ASCII は下表のように7ビットで構成され、94文字がアルファベット、数字、記号などの印刷可能な文字に、残りの34文字が空白文字(0x20)と制御コード(Control Code:0x00~0x1F,0x7F)に割り当てられています。

上表ASCIIで、例えば半角大文字の「A」と「Z」は、どのように2進数と対応させているかを見てみましょう。最上欄が上位3ビットを、左端欄が下位4ビットを、それぞれ16進数で表しています。
A:
0x41(16進数)= 100 0001(2進数7ビット)に対応
Z: 0x5A(16進数)= 101
1010(2進数7ビット)に対応
逆に、ASCIIコードから文字列への対応の例を示します。ASCIIコード16 進数で 「54 68 69 73 20
69 73 20 61 20 70 65 6E 2E」(16進数を示す0xは省略しています) は、「This is a pen.」 というテキストを意味します。
<日本語コード概説>
ASCIIコードは
7ビット(2の7乗=128文字を表現できます)でできています(8ビット目は使いません)が、1バイトコードと呼ぶこともあります。一般に文字コードは、扱い易い1バイト(8ビット,2の8乗=256文字を表現できます)を基準にして、「英数字1文字=1バイト」として規格を決めています。メモリやディスクの容量の単位が、バイト単位で扱われるのも頷けます。
ところで、漢字などはASCII
など1バイトコードでは収録できないため、日本や韓国、中国などではそれぞれ独自に2バイト(2の16乗=65,536文字を表現できます)のコード体系を定めています。
ここで問題があります。日本においても英数字のコードは、世界標準のASCIIコードを採用しています。ASCIIコード(1バイトコード)と、2バイトコードはそのままでは同居できません。例えば、16進数で「32
23」は 「横」という
1文字の日本語文字と解釈することも、「2#」という2文字の英文字と解釈することもできます。これでは困ります。
そこで、その解決法(符号化方式)がいくつか考えられました。日本工業規格(JIS)で標準化されたJISコード、パソコンで使われるシフトJIS、UNIXで使われるEUC(Extended
Unix
Code)の3種類が利用されています。
最近では、世界の主要な国の言語をサポートした2バイトの統一文字コード体系であるUnicode
の規格化が進み、一部で利用が始まっていいます。Unicodeは、これまで各国でばらばらに制定されてきた文字コードを統一するものとして期待されています。
<JISコード>
JISコード(JIS X
0202)は、7ビット128通りのコードのうち、ASCIIの空白文字と制御コードの34個を除いた94の符号を2つ組み合わせて、「文字セット」(ASCII/日本語など)を0x21~0x7Eの領域に割り当てた7ビットによる文字コードです。その結果、文字セットは94×94
=
8,836の空間に配置されることになります。
使用する文字セットは、「エスケープシーケンス」と呼ばれる特殊なコード(文字列)を目印にして切り替えて、ASCIIと日本語を共存させています。詳しくは、次のエントリーで触れることにします。
JISコードは実際には7ビットで表現されている(半角カナを除く)ため、欧米などで開発された電子メールシステム(7ビットASCII コードを使用している)でも使用することができます。JISコードはISOによる文字コードの国際標準の一つである「ISO-2022」の日本語部分にも採用され、「ISO-2022-JP」とも呼ばれます。
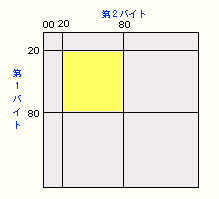
<シフトJISコード>
シフトJISコード(Shift-JIS)は、WindowsやMacなどでおなじみのパソコンで使われる文字コードです。特別な制御コードがなくても、1バイト文字と2バイト文字を共存できるようにするために、JISコードを移動(シフト)させたことからこのように呼ばれます。
シフトJISでは、先頭ビットが
1であるバイトがきたら、そのバイトと次のバイトがセットで日本語文字を表す、という解決法です。即ち、0x81~0x9F、0xE0~0xEFの範囲のバイトが現れると2バイトモードが開始され、このバイトは2バイト文字の第1バイトとして処理され、続く第2バイトは0x40~0x7E、0x80~0xFCの範囲に配置されています。このようにして、先頭ビットが0である英数字(ASCII、0x21~0x7E)や1バイト仮名(半角カナ、0xA1~0xDF)と、重複しないように配置されています。
シフトJISコードは、事実上日本で最も普及している文字コードであり、扱いが簡単というメリットがありますが、シフトJISは「ISO-2022」非準拠で8ビット目も使用しているため、電子メールで流すときはJISコードに変換しなければなりません。JISコードとは簡単なアルゴリズムで相互変換は可能です。
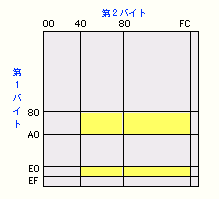
<EUCコード>
EUC コード(Extended Unix Code)
は、日本語対応UNIXワークステーションで内部コードとして広く使われています。第8ビットが0ならASCII、1ならJIS漢字と使い分けられるようにしています。
特長としては、エスケープシーケンスがない、第1バイトを見ただけで文字種がわかる、漢字の第2バイトがASCIIと重複しない、
などシフトJISと類似した点に加えて、
JISとのコード変換が容易なことがあげられます。
EUCは、128×256=32,768種類の日本語文字を表現できますが、JISやシフトJISとの大きな相違点は、半角カタカナが冷遇されていることです。
<Unicode>
Unicode は世界で使われる全ての文字を共通の文字集合にて利用できるようにしようという考えで作られた国際規格です。元々16ビットの文字集合で全ての文字の網羅を目指して開発されましたが、Unicode
2.0以降では21ビットの文字集合として規定されることとなりました。
Unicode のUCS(Universal Character Set:万国文字集合)で定義される文字集合の文字列をバイト列(数値の列)に変換する方式が、UTF (UCS
Transformation Format)です。UTF には、UTF-7,UTF-8,UTF-16などがあり、UTF-7 とUTF-8 の数値はUCS
をASCII に変換する際のビット数を示しています。また、UTF-8 は英数を1バイト、日本語は3バイトで表現し、UTF-16
は英数も日本語も全て2バイトで表現します。
電子メールとブラウザではUTF-8、OSの内部処理などにはUTF-16が使われています。また、データについては、WindowsとMac ではShift-JISを、LinuxではUTF-8が使用されています。
<メモ帳 Notepad の保存文字コード>
Windows2000,XP の「メモ帳」の文字コードは、
ANSI、Unicode、Unicode big endian、UTF-8 から保存形式が選択できるようになっています。
・ANSI:英数字はASCII と同じで、日本語はShift-JISコードで保存。
・Unicode:UTF-16 little endian のこと。
・Unicode
big endian:UTF-16 big endian のこと。
・UTF-8:UTF-16 big endian
をUTF-8形式に変換して保存。
UTF-16では2バイト文字の1バイト目を先に書く方法(big
endian)と、1バイト目を後に書く方法(little
endian)が用意されています。符号化された文書がUTF-16であるかどうかを識別するためと、endian
を識別するために、文書の先頭にはBOM(Byte Order Mark)と呼ばれる、バイト0xFEFFを付加します。little endianの場合は、ファイルの先頭2バイトが0xFF,0xFEとなり、big
endianなら0xFE,0xFFとなります。