<IT情報・コンピュータ基礎編> IT情報TOPヘ
ASCII あれこれ
(2006年05月01日)![]()
コンピュータはアメリカで発明され、アメリカで発展してきました。ASCIIコードも英語圏を前提に作られました。グローバルな今の世界では、なおさらASCIIコード抜きにコンピュータの利用はありえません。各国の文字コードはASCIIコードと併用せざるを得ないのです。
このエントリーでは、ASCIIコードにまつわる「あれこれ」をみていくことにします。
<制御コード>
前のエントリーでは、ASCIIコードの文字コードを中心にみてきました。下記に制御コードも含めたASCIIコード表の全体を示します。このコードが制定された当時は、コンピュータや通信の性能が悪く、またディスクの保存容量も少なかったため、少しでもムダな情報を省くため、多くの制御コードと、7ビットという中途半端なビット数の文字コード体系ができました。
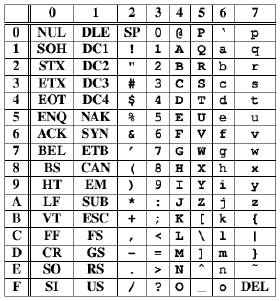
上表の0x00~0x7Fのうち、左の2列が制御コード、右6列の多くが文字コードになっています。ASCIIの制御コードは、もともと通信のためのコードですが、近年の複雑な通信制御では、その多くが使われなくなりました。
<改行コード>
「改行」をどの制御コードに対応させるか、これは大切なことです。改行の意を表すコードは、CR(Carriage
Return,0x0D)と LF(Line Feed, 0x0A)の2つがあります。タイプライター時代に、CR
は印字位置を行頭に移す、LF
は紙を送る(つまり印字位置を次の行に移す)ことを意味していました。
実は残念なことに、現在広く用いられているコンピュータ全ての間で一致した使い方になっていません。このように改行の意味を持つ2つのコードが存在していたことから、Windowsでは
CR+LF(2バイト)、MacintoshではCR、UNIXではLF
が改行を表現するという決まりになっています。それらの間でデータを交換したいときは、改行コードを変換する必要があります。
<エスケープシーケンス>
エスケープシーケンスはテキスト文字列中に埋め込み、その属性を切り替えるために使われる文字の並びです。エスケープシーケンスは、制御コードのESC(Escape,0x1B)で始まるためこのように呼ばれます。ここでは
JISコード(JIS X
0202)において、ASCII/漢字などの「文字セット」を切り替える方法について説明します。
JISコードでは、エスケープシーケンスによってそれ以降の文字を決定します。例えば、「1B
28 42」(16進数です)の3バイトを宣言すれば、以後、別のエスケープシーケンスが宣言されるまでの間は ASCII
文字の連続だ、という意味になります。また、文の始まりはASCIIと仮定します。
具体的には、次の4つの「文字セット」をエスケープシーケンスで切り替えています。
1バイト文字へのエスケープシーケンス
ASCII 1B 28 42 [ESC] (
B
JIS X 0201-1976 ローマ字 1B 28 4A [ESC] ( J
2バイト文字へのエスケープシーケンス
JIS X 0208-1983(新JIS) 1B 24 42 [ESC] $ B
JIS
C 6226-1978(旧JIS) 1B 24 40 [ESC] $ @
(例) 「12(1B 24
42)月(1B 28 42)24(1B 24 42)日はクリスマスイブ(1B 28
42)」では、斜字部分が埋め込まれたエスケープシーケンスです。その分だけ、EUC、シフトJIS に比べてファイルサイズが増えます。
<ISO 646>
ASCIIコードが英語の7ビットのままでは、他のヨーロッパ諸国や日本などでの利用に不便があるため、ISO
646ができました。ISO 646では、7ビットASCIIを基本に、下表のように12箇所は各国で文字コードの入れ替えを許可しています。

このように一部の文字コードを別の文字に入れ替えることで、アメリカのコンピュータ技術を別の国で利用できることになります。ヨーロッパ諸国では、この12文字に対し、それぞれの国の事情に沿った文字を割り当てた文字コードが使われています。
<日本のISO 646事情?>
日本では、JIS およびシフトJISコードのASCII部分を、ISO
646で変更が認められている12文字のうち、0x5C バックスラッシュ(\)を円記号(¥)に、0x7E
チルダ(~)をアッパーバー( ̄)に置き換えました・・・・そのはずでした。しかし、上表を見ると、0x5C は円記号(¥)になっていますが、0x7Eは
チルダ(~)のままですね。
たしか、数年前までの日本のパソコンのキーボードは、現在のキートップ「0,わ,を」には、他にチルダ(~)が書かれていました。また、現在の「^,~,へ」には、以前は「^, ̄,へ」と書かれていました。そしてチルダ(~)を入力するのに「Shift」+「~」ではダメで、「Shift」+「 ̄」を入力していました。
ところが、現在のWindowsやMacintoshのキーボードでは、チルダ(~)記号はキートップ「^,~,へ」へ移動しており、キートップ通り正しく入力されます。円記号(¥)は以前のまま変わっていません。おそらくURL表記にチルダを使うWebサイトが普及し始めた頃に、チルダだけ元に戻したんじゃないかと思います。詳しい方がいたら教えてください。
<ISO 8859>
ISO 646では、たかだか 12文字しか入れられない上に、ASCII
との文書互換性が失われてしまうという問題がありました。今日ではコンピュータの性能や通信環境が飛躍的に向上し、ディスク保存容量も大きくなり、情報の表現方法を余り気にしなくてもよい時代になりました。このような背景から、ISOでは文字コードを7ビットから8ビットに拡大しました。ISO
8859 です。
この規格は、8ビット前半のコード領域は、7ビットASCIIから拡張されたISO
646のままとし、8ビットの後半のコード領域128文字(0xA0~0xFF)に、各国固有の文字や記号を割り当てます。
しかし、ISO-8859
は、当初ヨーロッパ全域を視野に入れたものでしたが、不幸にも使われる文字数を低く見積もってしまいました。結局 128
文字ではヨーロッパの全文字を網羅できず、複数の ISO-8859 が生まれました。ISO 8859-1 ~ ISO 8859-10
まであり、現在のヨーロッパでは、日本と比べものにならないくらい文字化けの問題は深刻だといわれています。
このうちISO
8859-1 は、「Latin-1」とも呼ばれ、主要な西欧言語に対応するラテン文字セットで、既にASCII
に取って代わっています。英語・ドイツ語・フランス語などの西欧の主要な言語をカバーしているので、これらの言語に使われる文字を自由に混在させた文章もOKです。